
QEMU 2.5 has just been released, with
a lot of new features. As with the previous release, we have also created a
video changelog.
I plan to write a few blog posts explaining some of the things I have been working on. In this one I m going to talk about how to control the size of the qcow2 L2 cache. But first, let s see why that cache is useful.
The qcow2 file format
qcow2 is the main format for disk images used by QEMU. One of the features of this format is that its size grows on demand, and the disk space is only allocated when it is actually needed by the virtual machine.
A qcow2 file is organized in units of constant size called clusters. The virtual disk seen by the guest is also divided into guest clusters of the same size. QEMU defaults to 64KB clusters, but a different value can be specified when creating a new image:
qemu-img create -f qcow2 -o cluster_size=128K hd.qcow2 4G
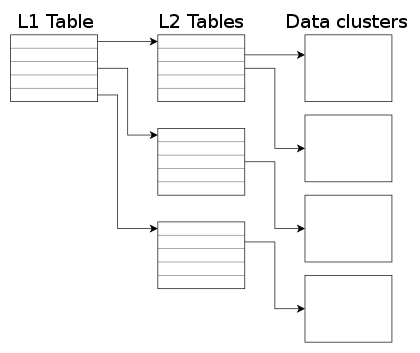
In order to map the virtual disk as seen by the guest to the qcow2 image in the host, the qcow2 image contains a set of tables organized in a two-level structure. These are called the L1 and L2 tables.
There is one single L1 table per disk image. This table is small and is always kept in memory.
There can be many L2 tables, depending on how much space has been allocated in the image. Each table is one cluster in size. In order to read or write data to the virtual disk, QEMU needs to read its corresponding L2 table to find out where that data is located. Since reading the table for each I/O operation can be expensive, QEMU keeps a cache of L2 tables in memory to speed up disk access.
The L2 cache can have a dramatic impact on performance. As an example, here s the number of I/O operations per second that I get with random read requests in a fully populated 20GB disk image:
| L2 cache size |
Average IOPS |
| 1 MB |
5100 |
| 1,5 MB |
7300 |
| 2 MB |
12700 |
| 2,5 MB |
63600 |
If you re using an older version of QEMU you might have trouble getting the most out of the qcow2 cache because of
this bug, so either upgrade to at least QEMU 2.3 or apply this patch.
(in addition to the L2 cache, QEMU also keeps a refcount cache. This is used for cluster allocation and internal snapshots, but I m not covering it in this post. Please refer to the qcow2 documentation if you want to know more about refcount tables)
Understanding how to choose the right cache size
In order to choose the cache size we need to know how it relates to the amount of allocated space.
The amount of virtual disk that can be mapped by the L2 cache (in bytes) is:
disk_size = l2_cache_size * cluster_size / 8
With the default values for cluster_size (64KB) that is
disk_size = l2_cache_size * 8192
So in order to have a cache that can cover
n GB of disk space with the default cluster size we need
l2_cache_size = disk_size_GB * 131072
QEMU has a default L2 cache of 1MB (1048576 bytes) so using the formulas we ve just seen we have
1048576 / 131072 = 8 GB of virtual disk covered by that cache. This means that if the size of your virtual disk is larger than 8 GB you can speed up disk access by increasing the size of the L2 cache. Otherwise you ll be fine with the defaults.
How to configure the cache size
Cache sizes can be configured using the
-drive option in the command-line, or the
blockdev-add QMP command.
There are three options available, and all of them take bytes:
- l2-cache-size: maximum size of the L2 table cache
- refcount-cache-size: maximum size of the refcount block cache
- cache-size: maximum size of both caches combined
There are two things that need to be taken into account:
- Both the L2 and refcount block caches must have a size that is a multiple of the cluster size.
- If you only set one of the options above, QEMU will automatically adjust the others so that the L2 cache is 4 times bigger than the refcount cache.
This means that these three options are equivalent:
-drive file=hd.qcow2,l2-cache-size=2097152
-drive file=hd.qcow2,refcount-cache-size=524288
-drive file=hd.qcow2,cache-size=2621440
Although I m not covering the refcount cache here, it s worth noting that it s used much less often than the L2 cache, so it s perfectly reasonable to keep it small:
-drive file=hd.qcow2,l2-cache-size=4194304,refcount-cache-size=262144
Reducing the memory usage
The problem with a large cache size is that it obviously needs more memory. QEMU has a separate L2 cache for each qcow2 file, so if you re using many big images you might need a considerable amount of memory if you want to have a reasonably sized cache for each one. The problem gets worse if you add backing files and snapshots to the mix.
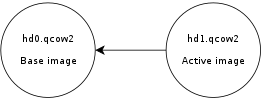
Consider this scenario:
Here,
hd0 is a fully populated disk image, and
hd1 a freshly created image as a result of a
snapshot operation. Reading data from this virtual disk will fill up the L2 cache of
hd0, because that s where the actual data is read from. However
hd0 itself is read-only, and if you write data to the virtual disk it will go to the active image,
hd1, filling up its L2 cache as a result. At some point you ll have in memory cache entries from
hd0 that you won t need anymore because all the data from those clusters is now retrieved from
hd1.
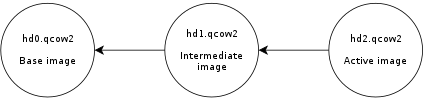
Let s now create a new live snapshot:
Now we have the same problem again. If we write data to the virtual disk it will go to
hd2 and its L2 cache will start to fill up. At some point a significant amount of the data from the virtual disk will be in
hd2, however the L2 caches of
hd0 and
hd1 will be full as a result of the previous operations, even if they re no longer needed.
Imagine now a scenario with several virtual disks and a long chain of qcow2 images for each one of them. See the problem?
I wanted to improve this a bit so I was working on a new setting that allows the user to reduce the memory usage by cleaning unused cache entries when they are not being used.
This new setting is available in QEMU 2.5, and is called
cache-clean-interval . It defines an interval (in seconds) after which all cache entries that haven t been accessed are removed from memory.
This example removes all unused cache entries every 15 minutes:
-drive file=hd.qcow2,cache-clean-interval=900
If unset, the default value for this parameter is 0 and it disables this feature.
Further information
In this post I only intended to give a brief summary of the qcow2 L2 cache and how to tune it in order to increase the I/O performance, but it is by no means an exhaustive description of the disk format.
If you want to know more about the qcow2 format here s a few links:
Acknowledgments
My work in QEMU is sponsored by
Outscale and has been made possible by
Igalia and the invaluable help of the QEMU development team.
Enjoy QEMU 2.5!
 What happened in the reproducible
builds effort this week:
What happened in the reproducible
builds effort this week:

 The second update in the 0.12.* series of
The second update in the 0.12.* series of  The package
The package 

 KDE
We will ship with at least KDE Applications 4.13, maybe some 4.14 things as well (if we are lucky, since Tanglu will likely be in feature-freeze when this stuff is released). The other KDE parts will remain on their latest version from the 4.x series. For Tanglu 3, we might update KDE SC 4.x to KDE Frameworks 5 and use Plasma 5 though.
GNOME
Due to the lack manpower on the GNOME flavor, GNOME will ship in the same version available in Debian Sid maybe with some stuff pulled from Experimental, where it makes sense. A GNOME flavor is planned to be available.
Common infrastructure
We currently run with systemd 208, but a switch to 210 is planned. Tanglu 2 also targets the X.org server in version 1.16. For more changes, stay tuned. The kernel release for Bartholomea is also not yet decided.
Artwork
Work on the default Tanglu 2 design has started as well any artwork submissions are most welcome!
Tanglu joins the OIN
The Tanglu project is now a proud member (licensee) of the
KDE
We will ship with at least KDE Applications 4.13, maybe some 4.14 things as well (if we are lucky, since Tanglu will likely be in feature-freeze when this stuff is released). The other KDE parts will remain on their latest version from the 4.x series. For Tanglu 3, we might update KDE SC 4.x to KDE Frameworks 5 and use Plasma 5 though.
GNOME
Due to the lack manpower on the GNOME flavor, GNOME will ship in the same version available in Debian Sid maybe with some stuff pulled from Experimental, where it makes sense. A GNOME flavor is planned to be available.
Common infrastructure
We currently run with systemd 208, but a switch to 210 is planned. Tanglu 2 also targets the X.org server in version 1.16. For more changes, stay tuned. The kernel release for Bartholomea is also not yet decided.
Artwork
Work on the default Tanglu 2 design has started as well any artwork submissions are most welcome!
Tanglu joins the OIN
The Tanglu project is now a proud member (licensee) of the The radio silence here on my blog has been not from lack of activity, but the inverse. Linux.conf.au chewed up the few remaining spare cycles I have had recently (after family and work), but not from organising the conference (been there, got the T-Shirt and the bag). So, let s do a run through of what has happened
The radio silence here on my blog has been not from lack of activity, but the inverse. Linux.conf.au chewed up the few remaining spare cycles I have had recently (after family and work), but not from organising the conference (been there, got the T-Shirt and the bag). So, let s do a run through of what has happened
 Good morning all my hungover friends.
New Hy release - sounds like the perfect thing to do while you re waiting for your headaches to go away.
Here s a short-list of the changes (from NEWS) - enjoy!
Good morning all my hungover friends.
New Hy release - sounds like the perfect thing to do while you re waiting for your headaches to go away.
Here s a short-list of the changes (from NEWS) - enjoy!
 I've
I've 










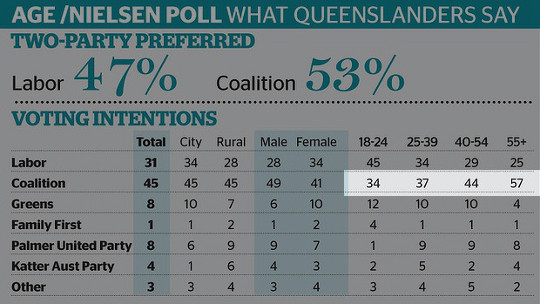 Big bad baby boomers
It is obvious that older voters prefer the conservative "coalition" parties, 57% of over-55s in particular. It is a huge jump from the 44% of voters in the age group below them.
What this table doesn't tell us is that Australia's population is top-heavy with
Big bad baby boomers
It is obvious that older voters prefer the conservative "coalition" parties, 57% of over-55s in particular. It is a huge jump from the 44% of voters in the age group below them.
What this table doesn't tell us is that Australia's population is top-heavy with  Altimeter Testing at Airfest
Bdale and I, along with AJ Towns and Mike Beattie, spent last weekend
in Argonia, Kansas, flying rockets with our Kloudbusters friends at
Altimeter Testing at Airfest
Bdale and I, along with AJ Towns and Mike Beattie, spent last weekend
in Argonia, Kansas, flying rockets with our Kloudbusters friends at




 It's almost one year since
It's almost one year since 
 It makes me wonder, if Mr Assange is genuinely guilty of rape despite his alleged victim
It makes me wonder, if Mr Assange is genuinely guilty of rape despite his alleged victim